UNKNOWN ORIGINS
The days of a consolidated feed from a vendor like a Bloomberg, or Refinitiv, which include multiple types of data points (Contributed Prices, Indicators of Interest (IoIs), Tradable Prices, Traded Prices) from a plethora of contributors to create data volume is certainly not over, but definitely being supplanted by an urgent need to know the data’s pedigree, and just as importantly what the data represents, i.e. ‘The Origin of the Data Species’
The question is why? And we can observe three fundamental factors, the first driving the second, leading to the third.
1.Regulators. Fundamental Review of the Trading Book (FRTB), and other regulations are now far more specific about what data is taken into financial institutions for risk, compliance, statutory reporting, and other purposes, and critically the regulators are now also defining the data characteristics. This means knowing all about data sources providing the information, and the type of data it is
2.Risk and Compliance. When an event that triggers a trade or flags a risk, it is based upon the data being ingested into the application creating that event. Now responsible managers want to know if the data triggering an event comes from a trusted source, for instance, is that FX trade being based upon a rate from Barclays or the Bank of Krakatoa? Using a consolidated feed there is no way of knowing who provided the price triggering the event
3.Defining the data sources in the market, and by pro-actively selecting preferred (and new) sources the Bank can have confidence in data provenance, apply decision tools and gain competitive advantages
This presentation analyses the origins of data and the importance of knowing its lineage to financial market players, what kind of price it is and how they fit into an overall data workflow.
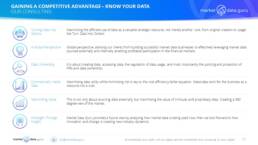
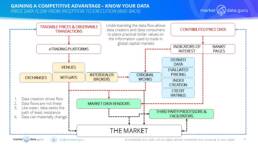
While necessarily simplistic the diagrams provide a look down view of the workflows, which we can be seen do not flow from top to bottom but are multi-linear in function
PRICE PUBLISHING CHANNELS
DATA TRANSPARENCY
The data creator also has options in deciding the most appropriate mechanisms for publishing their data, each of which is driven by overall market activity and liquidity. For highly liquid markets and exchanges, electronic trading has become the norm, and provides a constant data stream, complete with histories, but less liquid markets are often opaque, leading to a lack of data consistency.
There are three key types of price discovery data, all of which provide different views of the marketplace
1.Indicators of Interest – Data which is supplied by market participants like Banks and Inter-Dealer Brokers. They are usually not executable prices, but aimed at establishing price levels to stimulate liquidity and trading interest
2.Tradable Prices – Published prices where counter-parties can actively execute
3.Traded Prices – Executed prices
Unfortunately only fully electronic venues, like exchanges, manage to pick up all the prices, and if instruments can be traded via multiple platforms finding a complete picture can be difficult and/or expensive.
There are questions to be asked:
1.Whose data do you trust?
2.How to mitigate data risk?
3.What type of price drives the output?
So selecting the right price sources, especially in OTC markets, needs to be a strategic consideration.
CONTRIBUTED PRICING
PRICE DISCOVERY IN OTC MARKETS
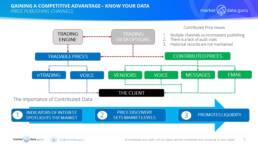
Defining contributed data helps to place a value on it, and understand its key function in price discovery. My personal definition is:
‘Contributed prices are the mechanism by which Banks and financial institutions publish prices for instruments, usually indicative, sometimes tradable, to indicate a market level at which they are willing to initiate a trade.’ It is the contributors ‘market shop window’.
While regulators quite rightly pursue the mantra of market transparency, this becomes problematic in Over-The-Counter (OTC) and less liquid markets where stimulation is required to overcome the lack of traded and tradable pricing to establish price levels. This is where Inter-Dealer Brokers come into their own by providing a vital role in price discovery, despite the regulators misconceived misgivings. It is noticeable that Banks have become more reluctant to provide indicators which has made price discovery in the less liquid markets harder.
The irony is in a desire for more transparency, for certain instrument pricing we see less.
As the below diagram demonstrates there are 3 elements to the process of contribution:

FUTURE DATA CONTENT SOURCING STRATEGIES
HOW TO GAIN THE ADVANTAGE
Knowing the data’s origins plugs directly into the business’ content strategy. Content acquisition has too often developed into a strategy of inertia, becoming an once-off process, first the consumer needs some data, gets it, and it simply remains in situ.
This unstructured approach is bad for the data sources, and data consumers, especially when sourcing in the vagaries of the OTC markets where consistency is an issue. Content sourcing in the future will be based on a continuous assessment of data quality in terms of accuracy, consistency, timeliness, and coverage throughout the contract cycle, utilising best practice data governance.
The key to effective content strategies is constant evaluation of the utility of both the sources and the data.
This will become even more important as more sources are made available within Cloud environments and not via traditional vendor channels.

SUMMARY
From this admittedly superficial analysis what we can determine is:
1.Data consumers need to not only know where their data ultimately came from, they need to understand the type of data it is, especially for OTC and less liquid markets
2.The differences in types of data, i.e. IOI, Tradable, and Traded factors into usage and decision tools
3.As markets change, so does the data sources and the data itself, therefore a constant process of validation is required to ensure the data ingested maintains its utility
4.Understanding data workflows and processes is a vital part of the knowing your data
5.Undervaluing one type of data in favour of another without good cause artificially limits the data’s usefulness
Context. The requirements for data should be driven by the business and how it defines its requirements to invest, therefore all participants in the data workflow needs to be involved in content strategies.
The competitive edge is driven by accessibility to a wider range of better quality data than ever before but can only be taken advantage of by understanding what the data is and what it represents.
Keiren Harris 17 May 2023
For information on our consulting services please email knharris@marketdata.guru
www.marketdata.guru/data-compliance
Please contact info@marketdata.guru for a pdf copy of the article
#snickerseffect #referencedata #marketdata #banks #solutions #analytics #ESG #Altdata #Cloud